F分布
2つの集団のばらつきを比較するための分布
難易度 Lv 3 / 10想定時間:約25分
できるようになること
- F分布が「2つのカイ二乗分布の比」として定義されることを説明できる
- 自由度の組 (d1,d2) による分布の形の変化を理解できる
- 分散の比較におけるF分布の役割を説明できる
2つのばらつきを比べたい
工場で製品の重さを管理している場面を考えます。製造ラインAとラインBがあり、それぞれの製品の重さにばらつきがあります。
「ラインAの方がラインBよりばらつきが大きいのでは?」という疑問を統計的に検証するには、2つの集団の分散を比較する方法が必要です。
カイ二乗分布の単元では、1つの集団の不偏分散 S2 と母分散 σ2 の関係を学びました。
σ2(n−1)S2∼χ2(n−1)
では、2つの集団の分散を比較するにはどうすればよいでしょうか。自然な発想は「分散の比」を取ることです。たとえばラインAの不偏分散が12、ラインBの不偏分散が4なら、比は 12/4=3 です。この「3」が偶然生じうる範囲なのか、それとも本当にばらつきに差があるのかを評価するための分布が必要になります。
この「分散の比」が従う分布が、F分布(F-distribution)です。
F分布の定義
U∼χ2(d1) と V∼χ2(d2) が独立のとき、
F=V/d2U/d1
で定義される F は自由度 (d1,d2) のF分布に従います。
F∼F(d1,d2)
つまりF分布は、2つの独立なカイ二乗分布をそれぞれの自由度で割った比です。
- d1:分子の自由度(第1自由度)
- d2:分母の自由度(第2自由度)
F分布は統計学者ロナルド・フィッシャー(Ronald Fisher)に敬意を表し、ジョージ・スネデカーが名づけました。分散分析(ANOVA: Analysis of Variance)の基盤として、実験計画法などで広く使われています。
F分布が成り立つための前提
| 前提 | 意味 |
|---|
| 1. 各母集団が正規分布に従う | 2つの母集団がともに正規分布に従う |
| 2. 2つの標本が独立 | 標本1と標本2が互いに影響しない |
| 3. 各標本内のデータが独立 | 各標本のデータが互いに独立に抽出されている |
母集団が正規分布に従わない場合、F検定の結果は信頼できません。F検定は正規性からの逸脱に敏感であり、この点はt検定よりも注意が必要です。
分布の形
F分布は自由度の組 (d1,d2) によって形が変わります。
- 値は常に 0 以上(比なので負にならない)
- d1 や d2 が小さい(例:F(2,5)):分布は0付近に集中し、右に裾が非常に長い
- d1,d2 がともに大きい(例:F(50,50)):1付近に集中し、対称に近づく
- 非対称な分布(正の歪度を持つ)
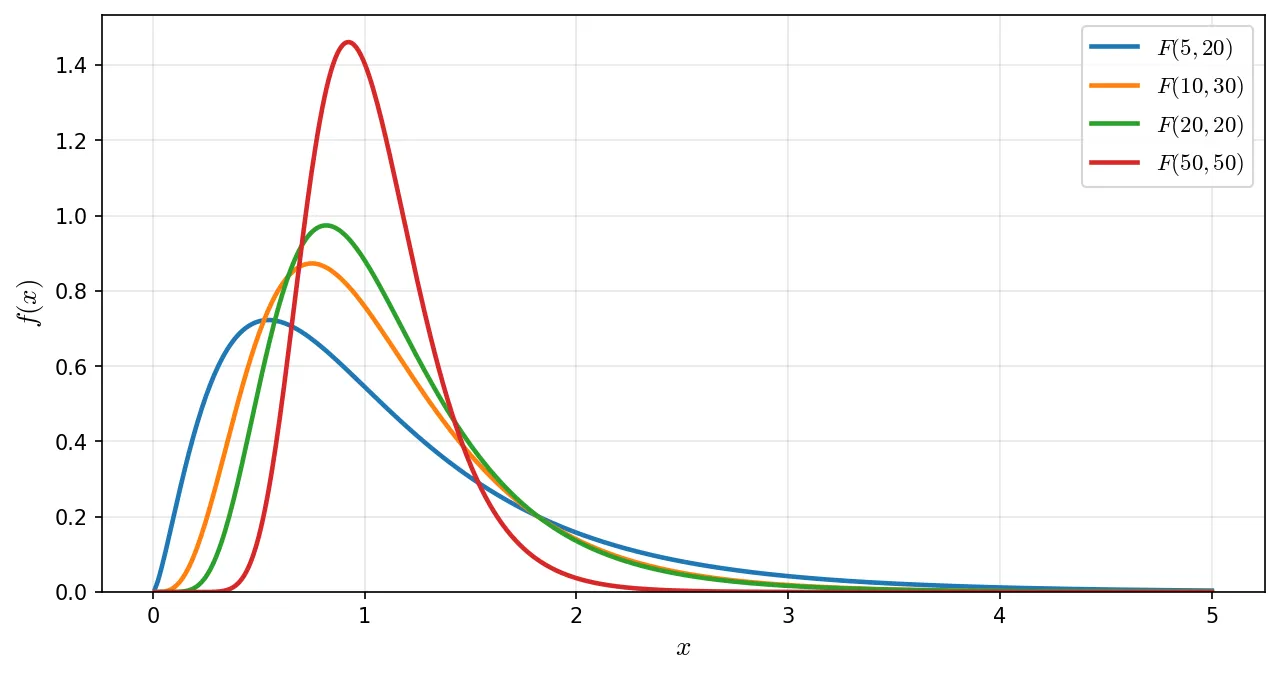
2つの母分散が等しいとき、分散の比は1に近い値を取りやすくなります。F分布の最頻値(ピーク)は1よりわずかに小さい位置にありますが、期待値は1よりわずかに大きくなります。この非対称性が、正の歪度を持つF分布の特徴です。
分散比検定との関係
2つの正規母集団から独立に標本を取ったとき、
- 標本1:サンプルサイズ n1、不偏分散 S12
- 標本2:サンプルサイズ n2、不偏分散 S22
帰無仮説 σ12=σ22 のもとで、
F=S22S12∼F(n1−1,n2−1)
は自由度 (n1−1,n2−1) のF分布に従います。
導出
2つの母集団がそれぞれ正規分布に従うと仮定すると、カイ二乗分布の単元で学んだ関係
σ12(n1−1)S12∼χ2(n1−1),σ22(n2−1)S22∼χ2(n2−1)
が成り立ちます。F分布の定義に当てはめると、
F=σ22(n2−1)S22/(n2−1)σ12(n1−1)S12/(n1−1)=S22/σ22S12/σ12
分子・分母の (n1−1)、(n2−1) がそれぞれ約分されて消えます。
帰無仮説 σ12=σ22 のもとでは σ12/σ22=1 なので、
F=S22S12
が得られます。
期待値と分散
F∼F(d1,d2) のとき、
- 期待値:E[F]=d2−2d2(d2>2)
- 分散:Var(F)=d1(d2−2)2(d2−4)2d22(d1+d2−2)(d2>4)
期待値は分子の自由度 d1 に依存せず、d2 が大きくなると1に近づきます。これは「2つの集団のばらつきが等しいなら、分散の比は1に近くなるはず」という直感と一致します。
例:F(10,30) のとき、E[F]=30/28≈1.07 です。分散の比なので、期待値は1に近い値です。
参考:確率密度関数
自由度 (d1,d2) のF分布の確率密度関数は次の式で表されます(x>0)。
f(x)=B(2d1,2d2)1(d2d1)d1/2xd1/2−1(1+d2d1x)−(d1+d2)/2
ここで B(a,b) はベータ関数です。実際の計算では統計ソフトやF分布表を使うため、この式を直接計算する必要はありません。
他の分布との関係
- カイ二乗分布:F(d1,d2) はカイ二乗分布2つの比として定義される
- t分布との関係:T∼t(k) のとき、T2∼F(1,k)
- d1=1:F分布は t2 と一致するため、平均の比較と分散の比較がつながる
- d1,d2→∞:F の値は1に確率収束する(分散が0に近づく)
よくある誤解
「F分布の自由度は入れ替えても同じ」
F(d1,d2) と F(d2,d1) は異なる分布です。分子と分母を入れ替えると、F 値の逆数 1/F が得られ、自由度も入れ替わります。
F∼F(d1,d2)⟹F1∼F(d2,d1)
この誤りが起きやすいのは、F分布表が上側確率(片側)のみ掲載されていることが多く、下側の臨界値を求める際に逆数と自由度の入れ替えを利用するためです。どちらの分散を分子に置いたかに注意してください。
まとめ
F分布 F(d1,d2) は、2つの独立なカイ二乗分布の比として定義される分布です。
F=V/d2U/d1
2つの正規母集団の分散が等しいかを検定するとき、不偏分散の比 S12/S22 がF分布に従うことを利用します。
t分布の2乗がF分布になるという関係は、カイ二乗分布・t分布・F分布が1つの体系をなしていることを示しています。F分布は分散比の検定だけでなく、分散分析(ANOVA)や回帰分析の有意性検定でも中心的な役割を果たします。